Stop patchworking, rethink conceptually - Does Data Protection need an updated architecture
Data Protection has been designed against simple risks and concepts. Ideas to suitably update its architecture.
TL:DR / Summary
- GDPR is subject to reforms recently; including its definition of “personal data”
- Suggested updates continue “patchworking”, i.e. adapting by minimal textual impact
- Subject to further exploration and elaboration, this article provides first illustrations on how to rethink GDPR's architecture conceptually
- Instead of extending the primary anchor “personal data” it is suggested to separate its different elements
- Instead of manipulating the static anchor to reflect dynamic technical and societal evolutions, identification will be considered a process with different levels of identification
- Each level of identification subsequently can be addressed with appropriate regulatory actions.

Status quo
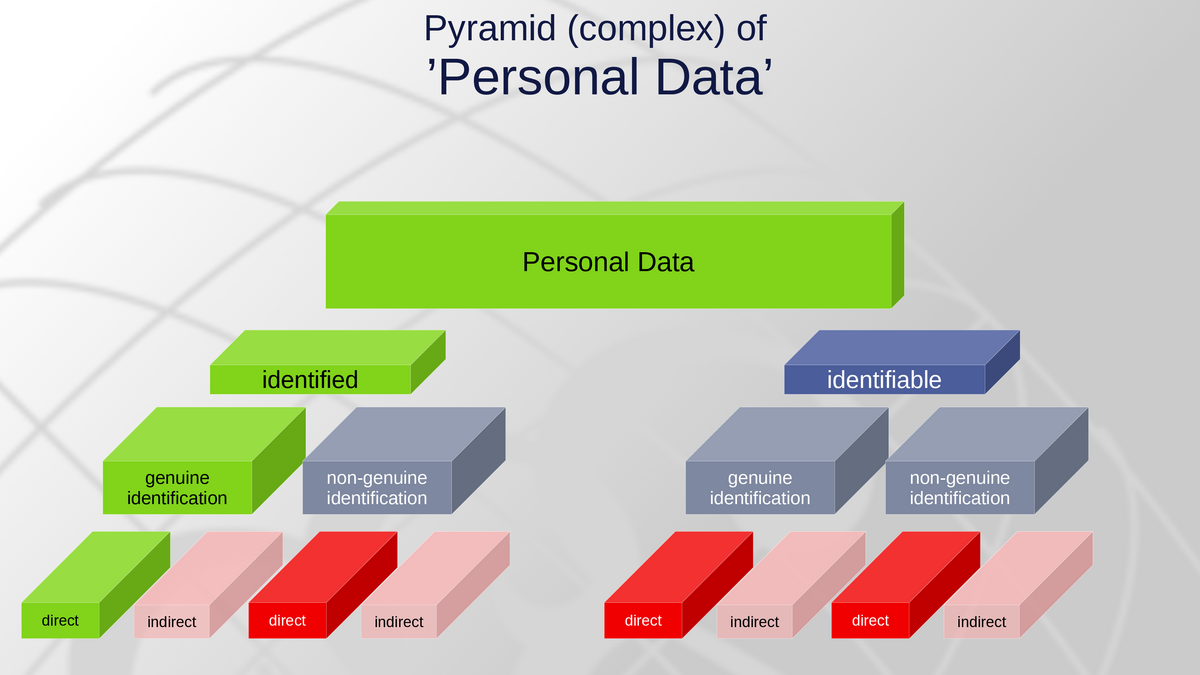
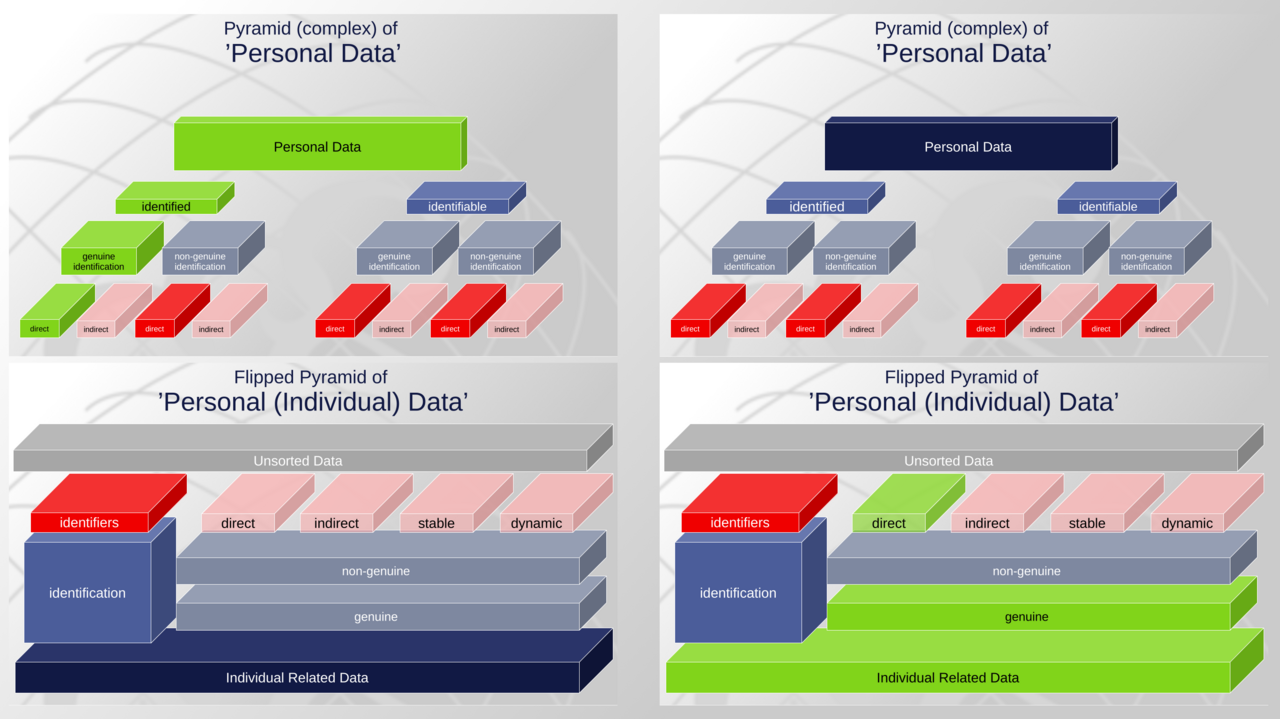
Currently, there is a conceptual pyramid with Personal Data at its top. Any other elements, such as identifiability, identifiers, etc. were designed in adapting and / or extending the the key term “personal data”.
If any of such relevant aspects are incorporated into the main referential term of the law, it becomes complex to refer to nuances of such term within the regulatory framework.
The “green” pattern reflects the original idea of personal data, when data protection was established. Any additional boxes were patched upon this concept, to address evolving risks due to technical or societal evolutions.
Suggested Approach
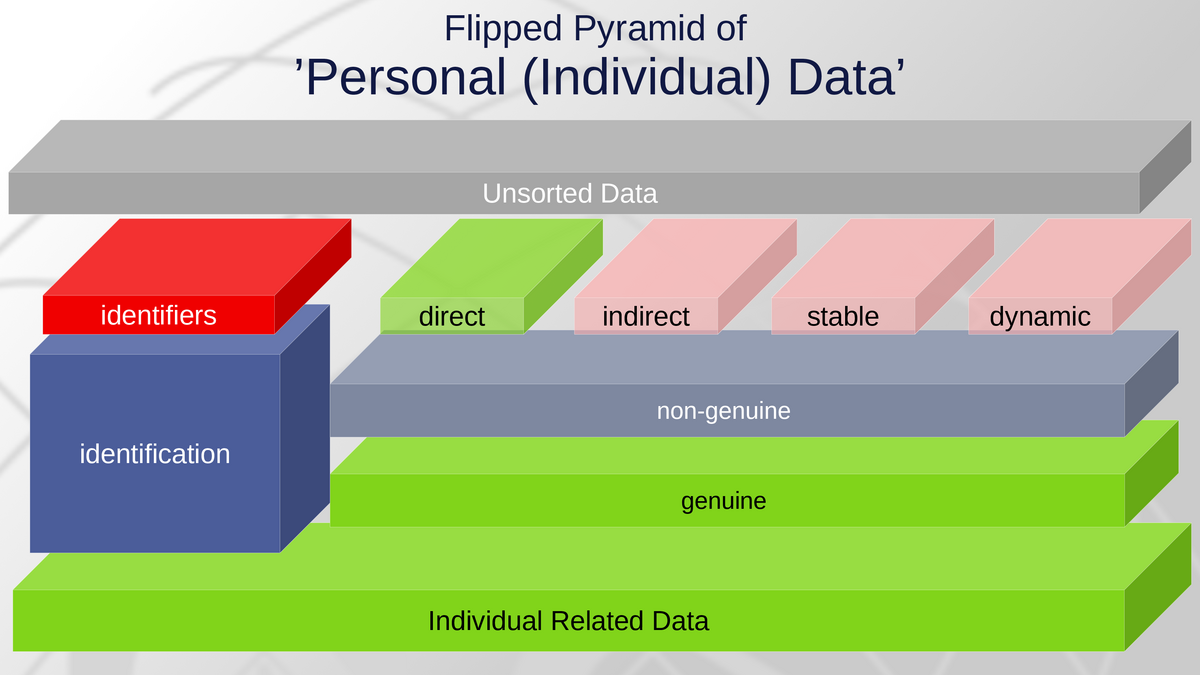
It is suggested to flip the pyramid. Instead of patching only one term - personal data - data protection becomes a gradient profile, along the risks and concepts developed in the past. As elements become more diverse they can be addressed more specifically in the regulatory framework.
At best, the level of data protection will remain high in those cases, where it was intended and where it is necessary. Likewise, those cases where “data protection” became recognised a bureaucratic burden without much added value, future regulatory frameworks may be designed more proportionate.
The “green” elements reflect the equivalent, of what has been addressed by data protection originally.
Conceptual Elements
The logic behind the updated architecture is an abstract perspective of currently relevant elements in determining personal data and associated risks. Those elements refer to
- identifiers,
- levels of identification, and
- levels of individualisation.
Scenarios "individualisation of data"
In respect of individualisation, there appear three types. For details, please, also read the Article “Opportunities to reduce bureaucracy under GDPR after CJEU in EDPS v. SRB (C-413/23 P)”.
- Individual Natural Person (genuine) - Fully (genuinely) identified, i.e., information related to one individual is processed, which can also be addressed in real life, either by postal address, name, ID- or Social Security-identifier, etc.
- Individual Natural Person (simply individualised) - Non-identified but individualised, i.e., information related to one individual is processed, to which there is no other additional identifiable information available, e.g., by simple non-registered device IDs, browser-fingerprint, unique UserID, etc.
Note: this scenario requires that none of the attributed information allows for further genuine identification; e.g., there must not be any (precise) location tracking, delivery address tracking, phone-numbers, or IP addresses, etc. - Individual Natural Person (non-genuine) - Non-identified but individualised, i.e., information related to one individual is processed, to which there is other additional identifiable information available, but not necessarily processed, e.g., by registered device IDs, IP-addresses, phone numbers, pseudonyms, etc.
Note: this scenario requires that none of the attributed information already genuinely identifies the individual but the already attributed information can be deducted or otherwise processed resulting into a genuinely identified individual.

Scenarios of "identification of individuals"
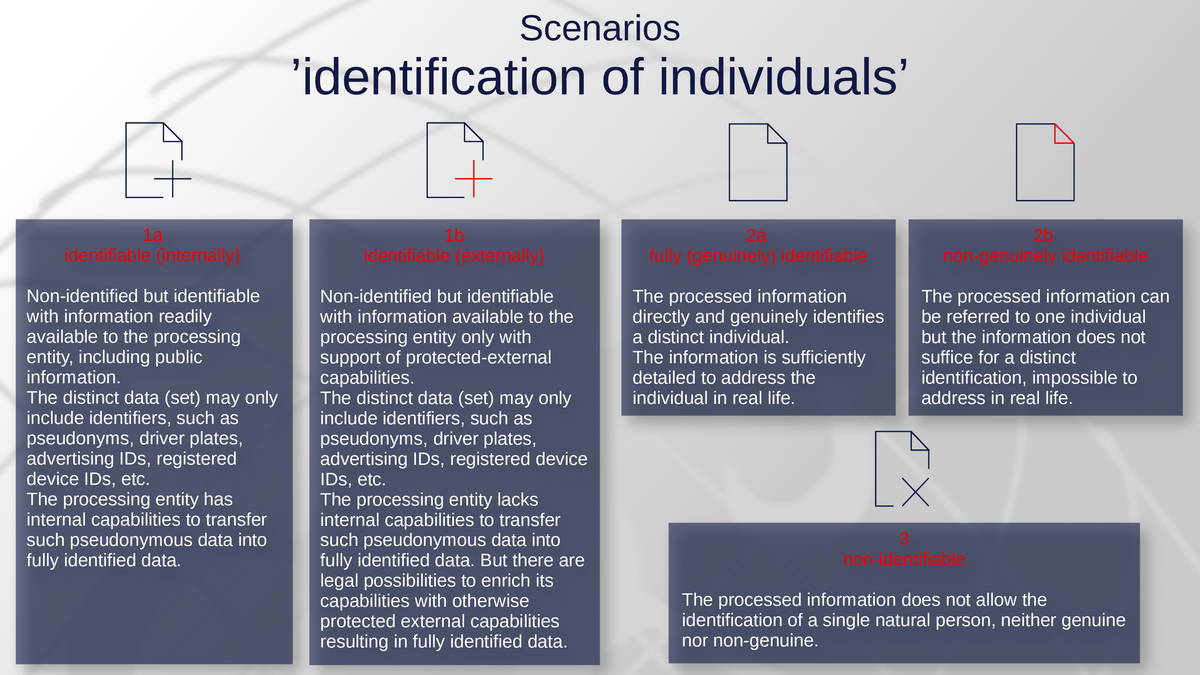
- 1a - identifiable (internally): Non-identified but identifiable with information readily available to the processing entity, including public information.
The distinct data (set) may only include identifiers, such as pseudonyms, driver plates, advertising IDs, registered device IDs, etc.
The processing entity has internal capabilities to transfer such pseudonymous data into fully identified data. - 1b - identifiable (externally): Non-identified but identifiable with information available to the processing entity only with support of protected-external capabilities.
The distinct data (set) may only include identifiers, such as pseudonyms, driver plates, advertising IDs, registered device IDs, etc.
The processing entity lacks internal capabilities to transfer such pseudonymous data into fully identified data. But there are legal possibilities to enrich its capabilities with otherwise protected external capabilities resulting in fully identified data. - 2a - fully (genuinely) identifiable: The processed information directly and genuinely identifies a distinct individual.
The information is sufficiently detailed to address the individual in real life. - 2b - non-genuinely identifiable: The processed information can be referred to one individual but the information does not suffice for a distinct identification, impossible to address in real life.
- 3 - non-identifiable: The processed information does not allow the identification of a single natural person, neither genuine nor non-genuine.
Scenarios "Types of Identifiers"
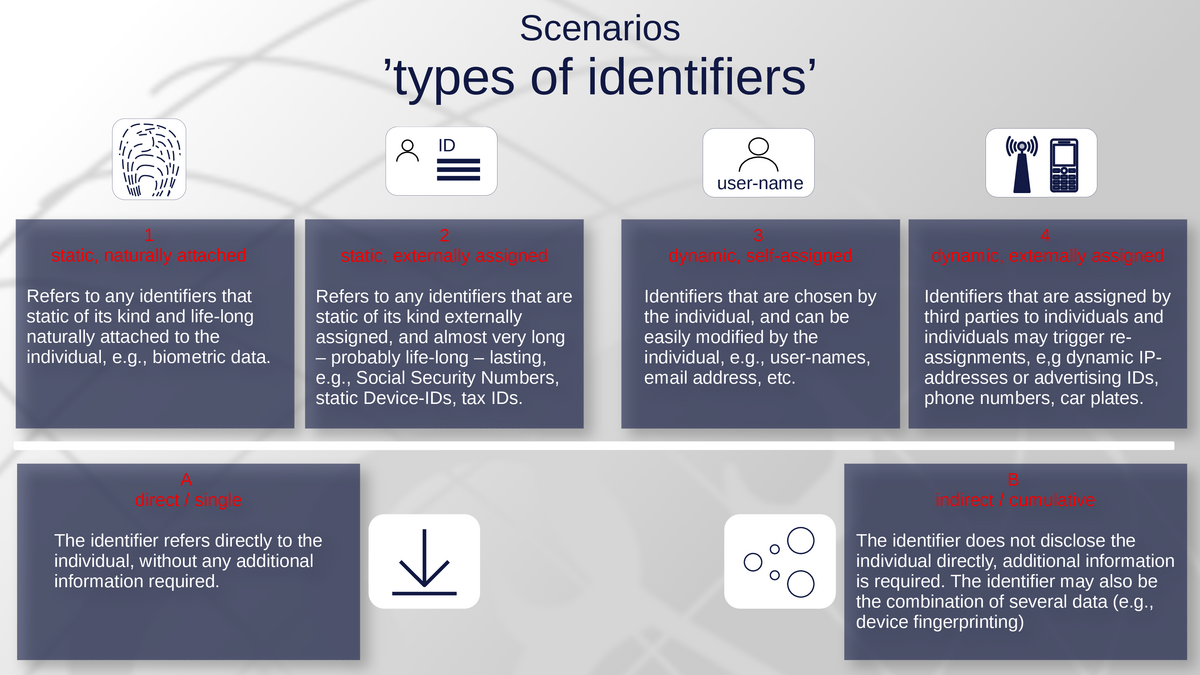
- static, naturally attached - Refers to any identifiers that static of its kind and life-long naturally attached to the individual, e.g., biometric data.
- static, externally assigned - Refers to any identifiers that are static of its kind externally assigned, and almost very long – probably life-long – lasting, e.g., Social Security Numbers, static Device-IDs, tax IDs.
- dynamic, self-assigned - Identifiers that are chosen by the individual, and can be easily modified by the individual, e.g., user-names, email address, etc.
- dynamic, externally assigned - Identifiers that are assigned by third parties to individuals and individuals may trigger re-assignments, e,g dynamic IP-addresses or advertising IDs, phone numbers, car plates.
- A - direct / single: The identifier refers directly to the individual, without any additional information required.
- B - indirect / cumulative: The identifier does not disclose the individual directly, additional information is required. The identifier may also be the combination of several data (e.g., device fingerprinting)
Next steps
The suggested architecture will require further analysis and fine-tuning. Subsequently, it must be transferred into legal provisions in order to further evaluate its practicality and interrelation with other provisions, such as Art. 6 GDPR or 9 GDPR.
X. Reference Guide
The suggested way to reference this article in any other (academic) publication is: Ingenrieth, Frank, Stop patchworking, rethink conceptually - Does Data Protection need an updated architecture, Document-ID: 2026-Q2-001, Permalink: https://ingenrieth-online.de/did-2026-q2-001